Introduction
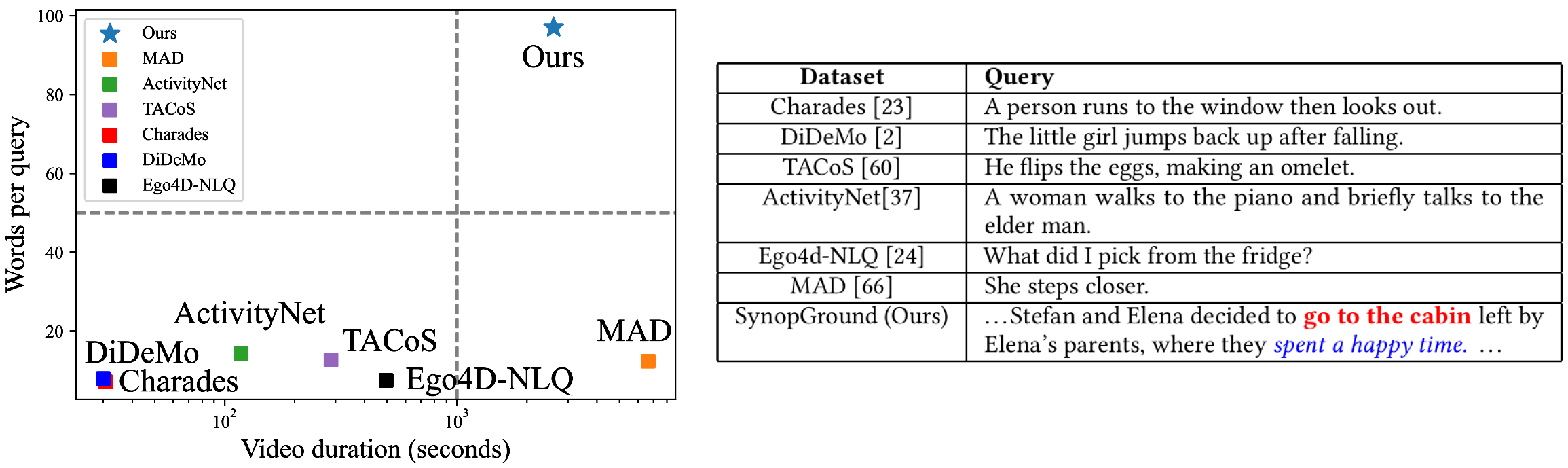
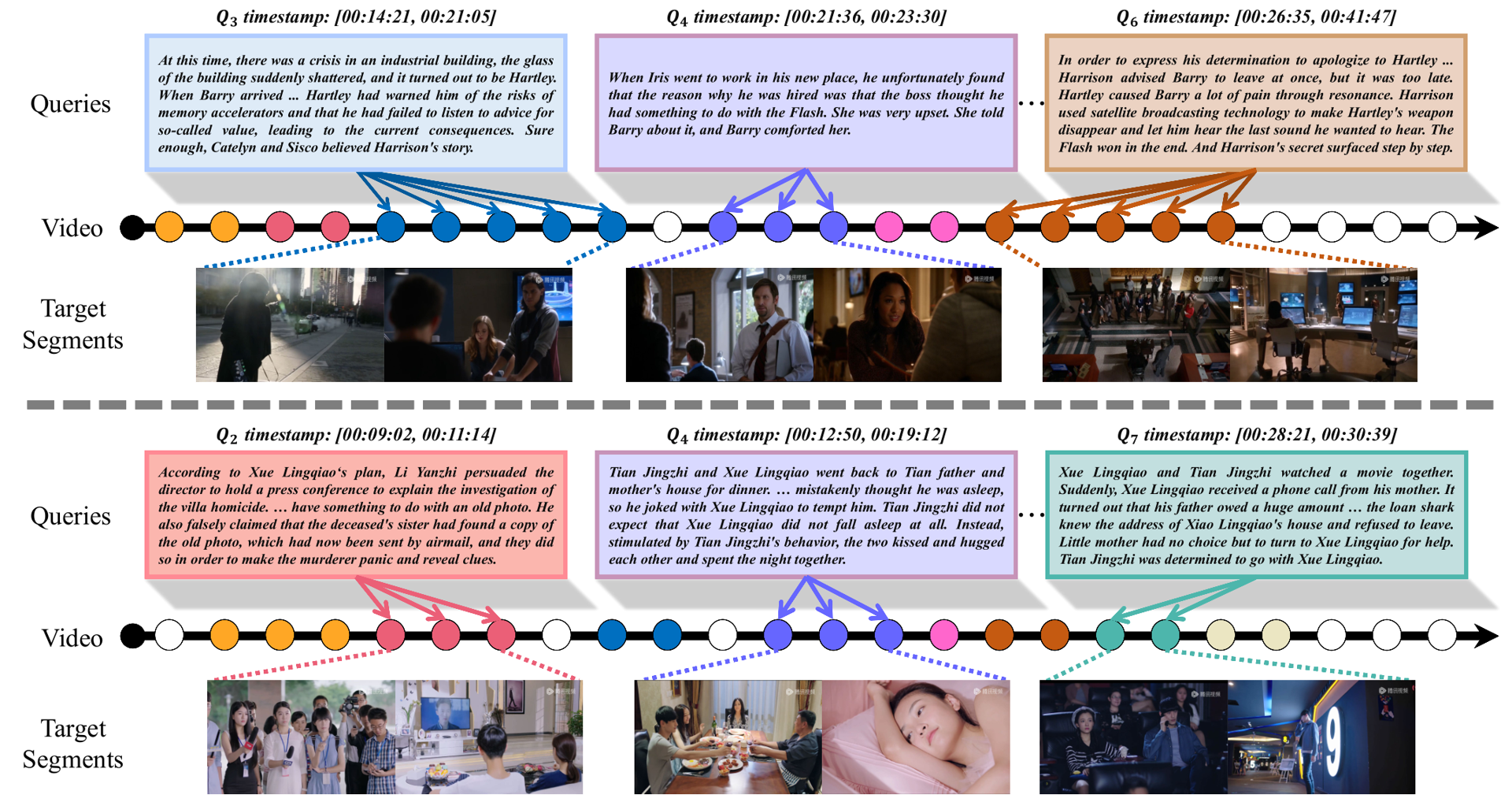
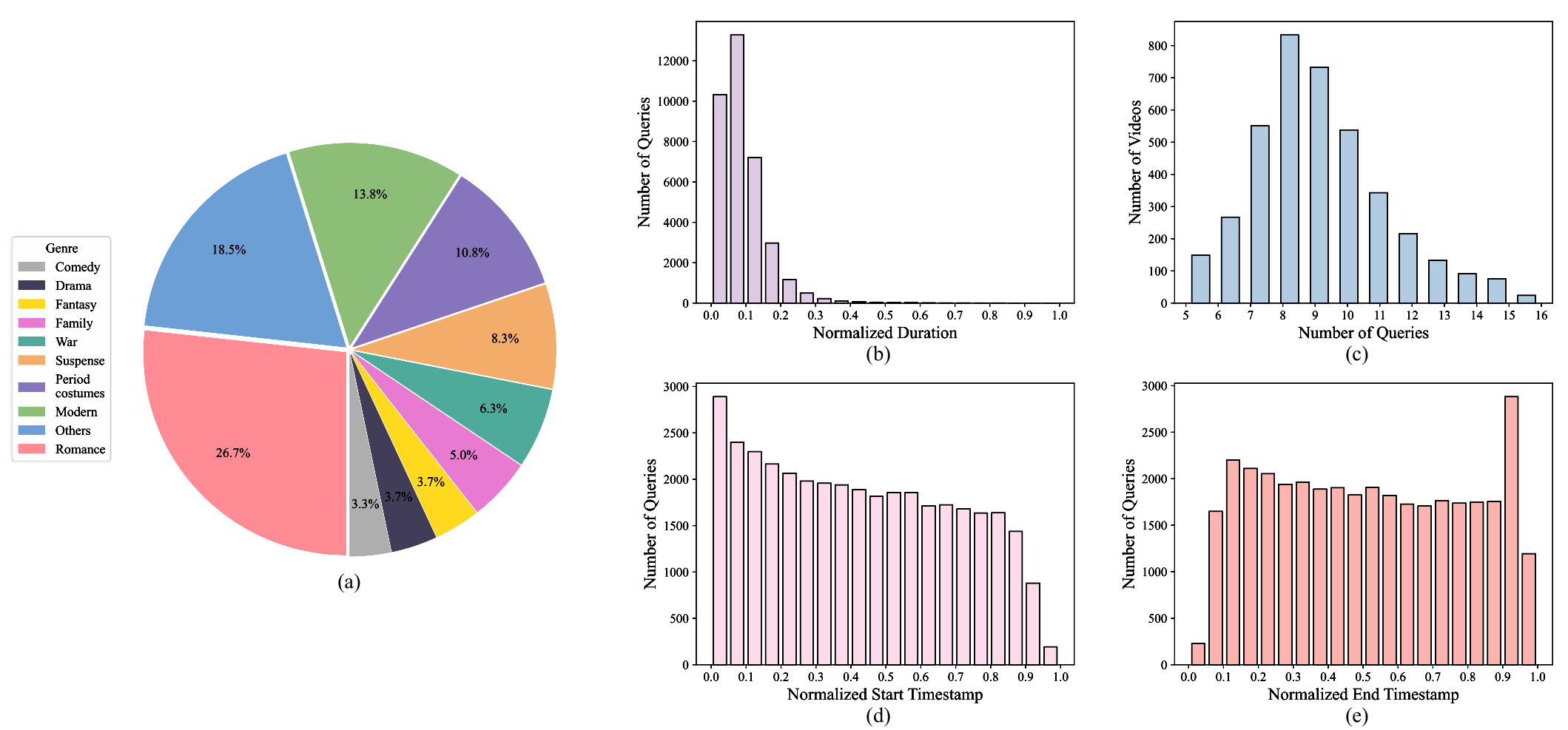
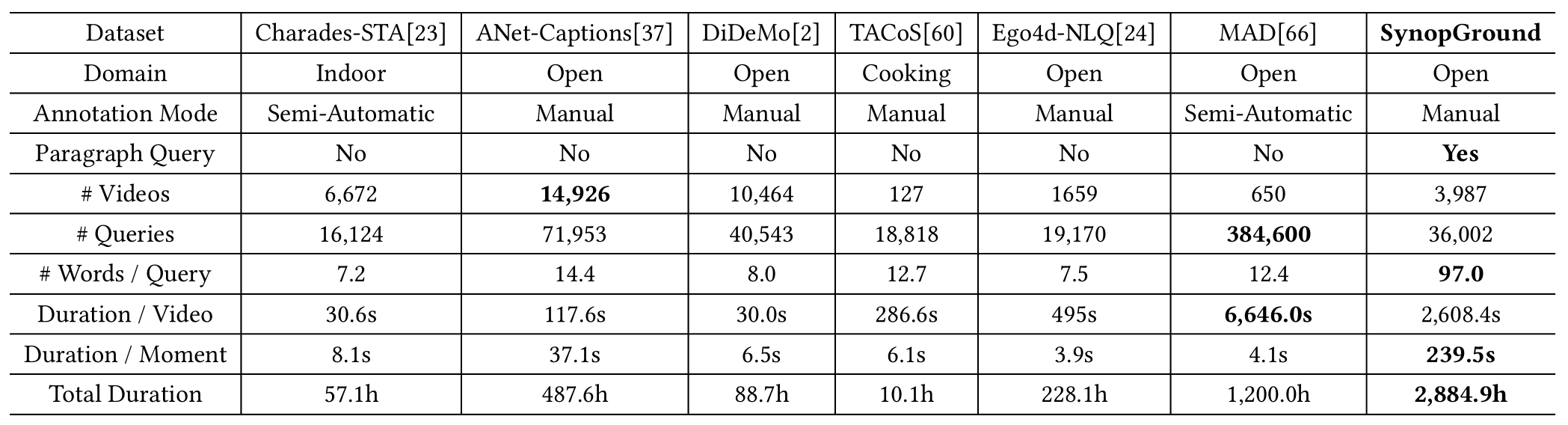
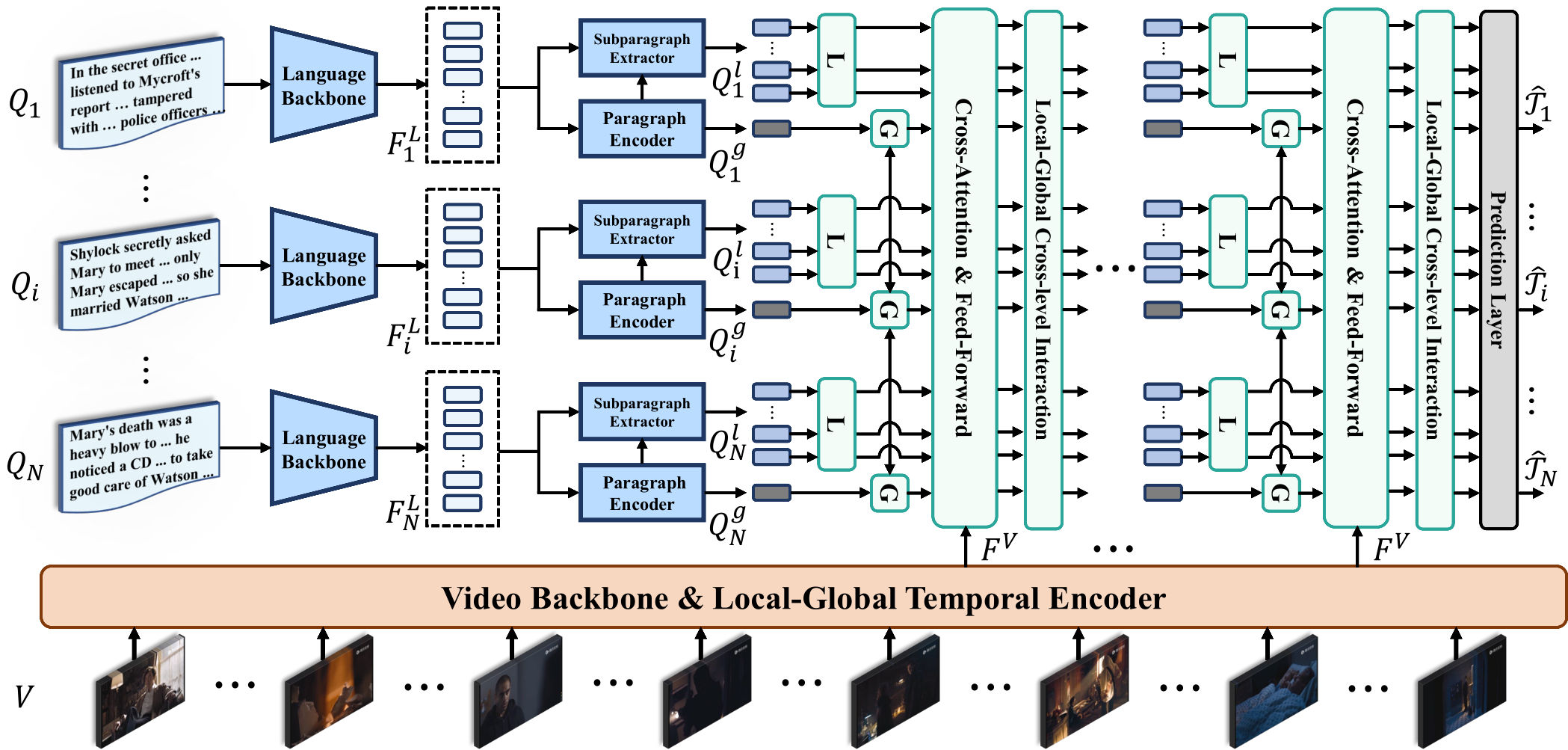
Currently, most of the commonly-used datasets are based on short videos and brief sentence queries. This setup limits the model in developing stronger abilities like long-term contextual multimodal understanding that bridges long-form videos and long-text queries. Besides, shorter queries that describe detailed events, are more prone to causing the risk of semantic ambiguity in referring expressions, i.e., the occurrence of one-to-many correspondence between queries and moments, which will adversely affect the model learning. In this work, we curate and present a large-scale dataset called SynopGround, in which over 2800 hours of narrative videos with human-written synopses are manually annotated with dense timestamps. Different from the short general descriptions like ``She steps closer.'' that are widely used in previous datasets, we use synopses involving both high-level expressions conveying abstract concepts and concrete descriptions picturing specific details. As shown in table above, there are very concrete descriptions for visible activity concepts like ``go to the cabin'', as well as extremely concise and abstract expressions like ``spent a happy time'' in the query from our dataset. Such language queries are more challenging, more unambiguous and can enforece the model to learn long-term cross-modal reasoning over higher-level concepts and storylines.